Как редактировать файл robots txt. Как редактировать файл robots txt Исходный код robots txt

Robots.txt - это текстовый файл, содержащий сведения для поисковых роботов, которые помогают проиндексировать страницы портала.
Больше видео на нашем канале - изучайте интернет-маркетинг с SEMANTICA
![]()
Представьте, что вы отправились за сокровищами на остров. У вас есть карта. Там указан маршрут: “Подойти к большому пню. От него сделать 10 шагов на восток, затем дойти до обрыва. Повернуть вправо, найти пещеру”.
Это - указания. Следуя им, вы идете по маршруту и находите клад. Примерно также работает и поисковой бот, когда начинает индексировать сайт или страницу. Он находит файл robots.txt. В нем считывает, какие страницы нужно проиндексировать, а какие - нет. И, следуя этим командам, он обходит портал и добавляет его страницы в индекс.
Для чего нужен robots.txt
Начинают ходить по сайтам и индексировать страницы после того, как сайт загружен на хостинг и прописаны dns. Они делают свою работу вне зависимости от того, есть у вас какие-то технические файлы или нет. Роботс указывает поисковикам, что при обходе веб-сайта нужно учитывать параметры, которые в нем находится.
Отсутствие файла robots.txt может привести к проблемам со скоростью обхода сайта и присутствия мусора в индексе. Некорректная настройка файла чревата исключением из индекса важных частей ресурса и присутствием в выдаче ненужных страниц.
Все это, как результат, ведет к проблемам с продвижением.
Рассмотрим подробнее, какие инструкции содержатся в этом файле, как они влияют на поведение бота у вас на сайте.
Как сделать robots.txt
Для начала проверьте, есть ли у вас этот файл.
Введите в адресной строке браузера адрес сайта и через слэш имя файла, например, https://www.xxxxx.ru/robots.txt
Если файл присутствует, то на экране появится список его параметров.

Если файла нет:
- Файл создается в обычном текстом редакторе типо блокнота или Notepad++.
- Нужно задать имя robots, расширение.txt. Внести данные с учетом принятых стандартов оформления.
- Можно проверить на предмет ошибок с помощью сервисов типа вебмастера Яндекса.Там нужно выбрать пункт «Анализ robots.txt» в разделе «Инструменты» и следовать подсказкам.
- Когда файл готов, залейте его в корневой каталог сайта.
Правила настройки
У поисковиков не один робот. Некоторые боты индексируют только текстовый контент, некоторые - только графический. Да и у самих поисковых систем схема работы краулеров может быть разной. При составлении файла это нужно учитывать.
Некоторые из них могут игнорировать часть правил, например, GoogleBot не реагирует на информацию о том, какое зеркало сайта считать главным. Но в целом, они воспринимают и руководствуются файлом.
Синтаксис файла
Параметры документа: имя робота (бота) «User-agent», директивы: разрешающая «Allow» и запрещающая «Disallow».
Сейчас есть две ключевых поисковых системы: Яндекс и Google, соответственно, важно при составлении сайта учитывать требования обеих.
Формат создания записей выглядит следующим образом, обратите внимание на обязательные пробелы и пустые строки.

Директива User-agent
Робот ищет записи, которые начинаются с User-agent, там должны содержаться указания на название поискового робота. Если оно не указано, считается, что доступ ботов неограничен.
Директивы Disallow и Allow
Если нужно запретить индексацию в robots.txt, используют Disallow. С ее помощью ограничивают доступ бота к сайту или некоторым разделам.
Если роботс.тхт не содержит ни одной запрещающей директивы «Disallow», считается, что разрешена индексация всего сайта. Обычно запреты прописываются после каждого бота отдельно.
Вся информация, которая указана после значка #, является комментариями и не считывается машиной.
Allow применяют, чтобы разрешить доступ.
Символ звездочка служит указанием на то, что относится ко всем: User-agent: *.
Такой вариант, наоборот, означает полный запрет индексации для всех.
Запрет на просмотр всего содержимого определенной папки-каталога
Для блокировки одного файла нужно указать его абсолютный путь
Директивы Sitemap, Host
Для Яндекса в принято указывать, какое зеркало вы хотите назначить главным. А Гугл, как мы помним, его игнорирует. Если зеркал нет, просто зафиксируйте, как считаете корректным писать имя вашего веб-сайта с www или без.
Директива Clean-param
Ее можно применять, если URL страниц веб-сайта содержат изменяемые параметры, не влияющие на их содержимое (это могут быть id пользователей, рефереров).
Например, в адресе страниц «ref» определяет источник трафика, т.е. указывает на то, откуда на сайт пришел посетитель. Для всех пользователей страница будет одинаковая.
Роботу можно указать на это, и он не будет загружать повторяющуюся информацию. Это снизит загруженность сервера.
Директива Crawl-delay
С помощью можно определить, с какой частотой бот будет загружать страницы для анализа. Эта команда применяется, когда сервер перегружен и указывает, что процесс обхода нужно ускорить.
Ошибки robots.txt
- Файл не находится в корневом каталоге. Глубже робот его искать не будет и не учтет.
- Буквы в названии должны быть маленькие латинские.
Ошибка в названии, иногда упускают букву S на конце и пишут robot. - Нельзя использовать кириллические символы в файле robots.txt. Если нужно указать домен на русском языке, используйте формат в специальной кодировке Punycode.
- Это метод преобразования доменных имен в последовательность ASCII-символов. Для этого можно воспользоваться специальными конвертерами.
Выглядит такая кодировка следующим образом:
сайт.рф = xn--80aswg.xn--p1ai
Дополнительную информацию, что закрывать в robots txt и по настройкам в соответствии с требованиями поисковиков Гугл и Яндекс можно найти в справочных документах. Для различных cms также могут быть свои особенности, это следует учесть.
Robots.txt – это специальный файл, расположенный в корневом каталоге сайта. Вебмастер указывает в нем, какие страницы и данные закрыть от индексации от поисковых систем. Файл содержит директивы, описывающие доступ к разделам сайта (так называемый стандарт исключений для роботов). Например, с его помощью можно установить различные настройки доступа для поисковых роботов, предназначенных для мобильных устройств и обычных компьютеров. Очень важно настроить его правильно.
Нужен ли robots.txt?
С помощью robots.txt можно:
- запретить индексирование похожих и ненужных страниц, чтобы не тратить краулинговый лимит (количество URL, которое может обойти поисковый робот за один обход). Т.е. робот сможет проиндексировать больше важных страниц.
- скрыть изображения из результатов поиска.
- закрыть от индексации неважные скрипты, файлы стилей и другие некритичные ресурсы страниц.
Если это помешает сканеру Google или Яндекса анализировать страницы, не блокируйте файлы.
Где лежит файл Robots.txt?
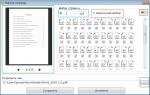
Если вы хотите просто посмотреть, что находится в файле robots.txt, то просто введите в адресной строке браузера: site.ru/robots.txt.
Физически файл robots.txt находится в корневой папке сайта на хостинге. У меня хостинг beget.ru , поэтому покажу расположения файла robots.txt на этом хостинге.

Как создать правильный robots.txt
Файл robots.txt состоит из одного или нескольких правил. Каждое правило блокирует или разрешает индексирование пути на сайте.
- В текстовом редакторе создайте файл с именем robots.txt и заполните его в соответствии с представленными ниже правилами.
- Файл robots.txt должен представлять собой текстовый файл в кодировке ASCII или UTF-8. Символы в других кодировках недопустимы.
- На сайте должен быть только один такой файл.
- Файл robots.txt нужно разместить в корневом каталоге сайта. Например, чтобы контролировать индексацию всех страниц сайта http://www.example.com/ , файл robots.txt следует разместить по адресу http://www.example.com/robots.txt . Он не должен находиться в подкаталоге (например, по адресу http://example.com/pages/robots.txt ). В случае затруднений с доступом к корневому каталогу обратитесь к хостинг-провайдеру. Если у вас нет доступа к корневому каталогу сайта, используйте альтернативный метод блокировки, например метатеги.
- Файл robots.txt можно добавлять по адресам с субдоменами (например, http://website .example.com/robots.txt) или нестандартными портами (например, http://example.com:8181 /robots.txt).
- Проверьте файл в сервисе Яндекс.Вебмастер и Google Search Console.
- Загрузите файл в корневую директорию вашего сайта.
Вот пример файла robots.txt с двумя правилами. Ниже есть его объяснение.
User-agent: Googlebot Disallow: /nogooglebot/ User-agent: * Allow: / Sitemap: http://www.example.com/sitemap.xml
Объяснение
- Агент пользователя с названием Googlebot не должен индексировать каталог http://example.com/nogooglebot/ и его подкаталоги.
- У всех остальных агентов пользователя есть доступ ко всему сайту (можно опустить, результат будет тем же, так как полный доступ предоставляется по умолчанию).
- Файл Sitemap этого сайта находится по адресу http://www.example.com/sitemap.xml.
Директивы Disallow и Allow
Чтобы запретить индексирование и доступ робота к сайту или некоторым его разделам, используйте директиву Disallow.
User-agent: Yandex Disallow: / # блокирует доступ ко всему сайту User-agent: Yandex Disallow: /cgi-bin # блокирует доступ к страницам, # начинающимся с "/cgi-bin"
В соответствии со стандартом перед каждой директивой User-agent рекомендуется вставлять пустой перевод строки.
Символ # предназначен для описания комментариев. Все, что находится после этого символа и до первого перевода строки не учитывается.
Чтобы разрешить доступ робота к сайту или некоторым его разделам, используйте директиву Allow
User-agent: Yandex Allow: /cgi-bin Disallow: / # запрещает скачивать все, кроме страниц # начинающихся с "/cgi-bin"
Недопустимо наличие пустых переводов строки между директивами User-agent, Disallow и Allow.
Директивы Allow и Disallow из соответствующего User-agent блока сортируются по длине префикса URL (от меньшего к большему) и применяются последовательно. Если для данной страницы сайта подходит несколько директив, то робот выбирает последнюю в порядке появления в сортированном списке. Таким образом, порядок следования директив в файле robots.txt не влияет на использование их роботом. Примеры:
# Исходный robots.txt: User-agent: Yandex Allow: /catalog Disallow: / # Сортированный robots.txt: User-agent: Yandex Disallow: / Allow: /catalog # разрешает скачивать только страницы, # начинающиеся с "/catalog" # Исходный robots.txt: User-agent: Yandex Allow: / Allow: /catalog/auto Disallow: /catalog # Сортированный robots.txt: User-agent: Yandex Allow: / Disallow: /catalog Allow: /catalog/auto # запрещает скачивать страницы, начинающиеся с "/catalog", # но разрешает скачивать страницы, начинающиеся с "/catalog/auto".
При конфликте между двумя директивами с префиксами одинаковой длины приоритет отдается директиве Allow.
Использование спецсимволов * и $
При указании путей директив Allow и Disallow можно использовать спецсимволы * и $, задавая, таким образом, определенные регулярные выражения.
Спецсимвол * означает любую (в том числе пустую) последовательность символов.
Спецсимвол $ означает конец строки, символ перед ним последний.
User-agent: Yandex Disallow: /cgi-bin/*.aspx # запрещает "/cgi-bin/example.aspx" # и "/cgi-bin/private/test.aspx" Disallow: /*private # запрещает не только "/private", # но и "/cgi-bin/private"
Директива Sitemap
Если вы используете описание структуры сайта с помощью файла Sitemap, укажите путь к файлу в качестве параметра директивы sitemap (если файлов несколько, укажите все). Пример:
User-agent: Yandex Allow: / sitemap: https://example.com/site_structure/my_sitemaps1.xml sitemap: https://example.com/site_structure/my_sitemaps2.xml
Директива является межсекционной, поэтому будет использоваться роботом вне зависимости от места в файле robots.txt, где она указана.
Робот запомнит путь к файлу, обработает данные и будет использовать результаты при последующем формировании сессий загрузки.
Директива Crawl-delay
Если сервер сильно нагружен и не успевает отрабатывать запросы робота, воспользуйтесь директивой Crawl-delay. Она позволяет задать поисковому роботу минимальный период времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей.
Перед тем, как изменить скорость обхода сайта, выясните к каким именно страницам робот обращается чаще.
- Проанализируйте логи сервера. Обратитесь к сотруднику, ответственному за сайт, или к хостинг-провайдеру.
- Посмотрите список URL на странице Индексирование → Статистика обхода в Яндекс.Вебмастере (установите переключатель в положение Все страницы).
Если вы обнаружите, что робот обращается к служебным страницам, запретите их индексирование в файле robots.txt с помощью директивы Disallow. Это поможет снизить количество лишних обращений робота.
Директива Clean-param
Директива работает только с роботом Яндекса.
Если адреса страниц сайта содержат динамические параметры, которые не влияют на их содержимое (идентификаторы сессий, пользователей, рефереров и т. п.), вы можете описать их с помощью директивы Clean-param.
Робот Яндекса, используя эту директиву, не будет многократно перезагружать дублирующуюся информацию. Таким образом, увеличится эффективность обхода вашего сайта, снизится нагрузка на сервер.
Например, на сайте есть страницы:
Www.example.com/some_dir/get_book.pl?ref=site_1&book_id=123 www.example.com/some_dir/get_book.pl?ref=site_2&book_id=123 www.example.com/some_dir/get_book.pl?ref=site_3&book_id=123
Параметр ref используется только для того, чтобы отследить с какого ресурса был сделан запрос и не меняет содержимое, по всем трем адресам будет показана одна и та же страница с книгой book_id=123. Тогда, если указать директиву следующим образом:
User-agent: Yandex Disallow: Clean-param: ref /some_dir/get_book.pl
робот Яндекса сведет все адреса страницы к одному:
Www.example.com/some_dir/get_book.pl?book_id=123
Если на сайте доступна такая страница, именно она будет участвовать в результатах поиска.
Синтаксис директивы
Clean-param: p0[&p1&p2&..&pn]В первом поле через символ & перечисляются параметры, которые роботу не нужно учитывать. Во втором поле указывается префикс пути страниц, для которых нужно применить правило.
Примечание. Директива Clean-Param является межсекционной, поэтому может быть указана в любом месте файла robots.txt. В случае, если директив указано несколько, все они будут учтены роботом.
Префикс может содержать регулярное выражение в формате, аналогичном файлу robots.txt, но с некоторыми ограничениями: можно использовать только символы A-Za-z0-9.-/*_. При этом символ * трактуется так же, как в файле robots.txt: в конец префикса всегда неявно дописывается символ *. Например:
Clean-param: s /forum/showthread.php
Регистр учитывается. Действует ограничение на длину правила - 500 символов. Например:
Clean-param: abc /forum/showthread.php Clean-param: sid&sort /forum/*.php Clean-param: someTrash&otherTrash
Директива HOST
На данный момент Яндекс прекратил поддержку данной директивы.
Правильный robots.txt: настройка
Содержимое файла robots.txt отличается в зависимости от типа сайта (интернет-магазин, блог), используемой CMS, особенностей структуры и ряда других факторов. Поэтому заниматься созданием данного файла для коммерческого сайта, особенно если речь идет о сложном проекте, должен SEO-специалист с достаточным опытом работы.
Неподготовленный человек, скорее всего, не сможет принять правильного решения относительно того, какую часть содержимого лучше закрыть от индексации, а какой позволить появляться в поисковой выдаче.
Правильный Robots.txt пример для WordPress
User-agent: * # общие правила для роботов, кроме Яндекса и Google, # т.к. для них правила ниже Disallow: /cgi-bin # папка на хостинге Disallow: /? # все параметры запроса на главной Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет, # правило можно удалить) Disallow: *?s= # поиск Disallow: *&s= # поиск Disallow: /search/ # поиск Disallow: /author/ # архив автора Disallow: /users/ # архив авторов Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой # ссылки на статью Disallow: */feed # все фиды Disallow: */rss # rss фид Disallow: */embed # все встраивания Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer (если не используете, # правило можно удалить) Disallow: /xmlrpc.php # файл WordPress API Disallow: *utm*= # ссылки с utm-метками Disallow: *openstat= # ссылки с метками openstat Allow: */uploads # открываем папку с файлами uploads Sitemap: http://site.ru/sitemap.xml # адрес карты сайта User-agent: GoogleBot # правила для Google (комментарии не дублирую) Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Disallow: *utm*= Disallow: *openstat= Allow: */uploads Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета) Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета) Allow: /wp-*.png # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д. Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS User-agent: Yandex # правила для Яндекса (комментарии не дублирую) Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /wp-admin/admin-ajax.php Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать # от индексирования, а удалять параметры меток, # Google такие правила не поддерживает Clean-Param: openstat # аналогичноRobots.txt пример для Joomla
User-agent: *
Disallow: /administrator/
Disallow: /cache/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /xmlrpc/
Robots.txt пример для Bitrix
User-agent: *
Disallow: /*index.php$
Disallow: /bitrix/
Disallow: /auth/
Disallow: /personal/
Disallow: /upload/
Disallow: /search/
Disallow: /*/search/
Disallow: /*/slide_show/
Disallow: /*/gallery/*order=*
Disallow: /*?print=
Disallow: /*&print=
Disallow: /*register=
Disallow: /*forgot_password=
Disallow: /*change_password=
Disallow: /*login=
Disallow: /*logout=
Disallow: /*auth=
Disallow: /*?action=
Disallow: /*action=ADD_TO_COMPARE_LIST
Disallow: /*action=DELETE_FROM_COMPARE_LIST
Disallow: /*action=ADD2BASKET
Disallow: /*action=BUY
Disallow: /*bitrix_*=
Disallow: /*backurl=*
Disallow: /*BACKURL=*
Disallow: /*back_url=*
Disallow: /*BACK_URL=*
Disallow: /*back_url_admin=*
Disallow: /*print_course=Y
Disallow: /*COURSE_ID=
Disallow: /*?COURSE_ID=
Disallow: /*?PAGEN
Disallow: /*PAGEN_1=
Disallow: /*PAGEN_2=
Disallow: /*PAGEN_3=
Disallow: /*PAGEN_4=
Disallow: /*PAGEN_5=
Disallow: /*PAGEN_6=
Disallow: /*PAGEN_7=
Disallow: /*PAGE_NAME=search
Disallow: /*PAGE_NAME=user_post
Disallow: /*PAGE_NAME=detail_slide_show
Disallow: /*SHOWALL
Disallow: /*show_all=
Sitemap: http://путь к вашей карте XML формата
Robots.txt пример для MODx
User-agent: *
Disallow: /assets/cache/
Disallow: /assets/docs/
Disallow: /assets/export/
Disallow: /assets/import/
Disallow: /assets/modules/
Disallow: /assets/plugins/
Disallow: /assets/snippets/
Disallow: /install/
Disallow: /manager/
Sitemap: http://site.ru/sitemap.xml
Robots.txt пример для Drupal
User-agent: *
Disallow: /database/
Disallow: /includes/
Disallow: /misc/
Disallow: /modules/
Disallow: /sites/
Disallow: /themes/
Disallow: /scripts/
Disallow: /updates/
Disallow: /profiles/
Disallow: /profile
Disallow: /profile/*
Disallow: /xmlrpc.php
Disallow: /cron.php
Disallow: /update.php
Disallow: /install.php
Disallow: /index.php
Disallow: /admin/
Disallow: /comment/reply/
Disallow: /contact/
Disallow: /logout/
Disallow: /search/
Disallow: /user/register/
Disallow: /user/password/
Disallow: *register*
Disallow: *login*
Disallow: /top-rated-
Disallow: /messages/
Disallow: /book/export/
Disallow: /user2userpoints/
Disallow: /myuserpoints/
Disallow: /tagadelic/
Disallow: /referral/
Disallow: /aggregator/
Disallow: /files/pin/
Disallow: /your-votes
Disallow: /comments/recent
Disallow: /*/edit/
Disallow: /*/delete/
Disallow: /*/export/html/
Disallow: /taxonomy/term/*/0$
Disallow: /*/edit$
Disallow: /*/outline$
Disallow: /*/revisions$
Disallow: /*/contact$
Disallow: /*downloadpipe
Disallow: /node$
Disallow: /node/*/track$
Disallow: /*&
Disallow: /*%
Disallow: /*?page=0
Disallow: /*section
Disallow: /*order
Disallow: /*?sort*
Disallow: /*&sort*
Disallow: /*votesupdown
Disallow: /*calendar
Disallow: /*index.php
Allow: /*?page=
Disallow: /*?
Sitemap: http://путь к вашей карте XML формата
ВНИМАНИЕ!
CMS постоянно обновляются. Возможно, понадобиться закрыть от индексации другие страницы. В зависимости от цели, запрет на индексацию может сниматься или, наоборот, добавляться.
Проверить robots.txt
У каждого поисковика свои требования к оформлению файла robots.txt.
Для того, чтобы проверить robots.txt на корректность синтаксиса и структуры файла, можно воспользоваться одной из онлайн-служб. К примеру, Яндекс и Google предлагают собственные сервисы анализа сайта для вебмастеров, которые включают анализ robots.txt:
Проверка robotx.txt для поискового робота Яндекса
Сделать это можно при помощи специального инструмента от Яндекс - Яндекс.Вебмастер , еще и двумя вариантами.
Вариант 1:
Справа вверху выпадающий список – выберите Анализ robots.txt или по ссылке http://webmaster.yandex.ru/robots.xml
Не стоит забывать о том, что все изменения, которые вы вносите в файл robots.txt, будут доступны не сразу, а спустя лишь некоторое время.
Проверка robotx.txt для поискового робота Google
- В Google Search Console выберите ваш сайт, перейдите к инструменту проверки и просмотрите содержание файла robots.txt . Синтаксические и логические ошибки в нем будут выделены, а их количество – указано под окном редактирования.
- Внизу на странице интерфейса укажите нужный URL в соответствующем окне.
- В раскрывающемся меню справа выберите робота .
- Нажмите кнопку ПРОВЕРИТЬ .
- Отобразится статус ДОСТУПЕН или НЕДОСТУПЕН . В первом случае роботы Google могут переходить по указанному вами адресу, а во втором – нет.
- При необходимости внесите изменения в меню и выполните проверку заново. Внимание! Эти исправления не будут автоматически внесены в файл robots.txt на вашем сайте.
- Скопируйте измененное содержание и добавьте его в файл robots.txt на вашем веб-сервере.
Кроме сервисов проверки от Яндекс и Google, существует множество других онлайн валидаторов robots.txt.
Генераторы robots.txt
- Сервис от SEOlib.ru .С помощью данного инструмента можно быстро получить и проверить ограничения в файле Robots.txt.
- Генератор от pr-cy.ru .В результате работы генератора Robots.txt вы получите текст, который необходимо сохранить в файл под названием Robots.txt и загрузить в корневой каталог вашего сайта.
Это текстовый файл (документ в формате.txt), содержащий четкие инструкции для индексации конкретного сайта. Файл указывает поисковиками, какие страницы веб-ресурса необходимо проиндексировать, а какие запретить к индексации.
Казалось бы, зачем запрещать индексировать какое-то содержимое сайта? Пусть поисковый робот индексирует все без разбору, руководствуясь принципом: чем больше страниц, тем лучше! Но это не так.
Далеко не весь контент, из которого состоит сайт, нужен поисковым роботам. Есть системные файлы, есть дубликаты страниц, есть рубрики ключевых слов и много чего еще есть, что вовсе не обязательно индексировать. В противном случае не исключена следующая ситуация.
Поисковый робот, придя к вам на сайт, первым долгом пытается отыскать пресловутый robots.txt. Если этот файл им не обнаружен или обнаружен, но при этом он составлен неправильно (без необходимых запретов), «посланник» поисковой системы начинает изучать сайт по своему собственному усмотрению.
В процессе такого изучения он индексирует все подряд и далеко не факт, что начинает он с тех страниц, которые нужно вводить в поиск в первую очередь (новые статьи, обзоры, фотоотчеты и т.д.). Естественно, что в таком случае индексация нового сайта может несколько затянуться.
Дабы избежать такой незавидной участи, веб-мастеру необходимо вовремя позаботиться о создании правильного файла robots.txt.
«User-agent:» – основная директива robots.txt
На практике в robots.txt с помощью специальных терминов прописываются директивы (команды), главной среди которых можно считать директиву «User-agent: ». Последняя используется для конкретизации поискового робота, которому в дальнейшем будут даваться те или иные указания. Например:
- User-agent: Googlebot – все команды, которые последуют после этой базовой директивы, будет касаться исключительно поисковой системы Google (ее индексирующего робота);
- User-agent: Yandex – адресат в данном случае отечественный поисковик Яндекс.
В файле robots.txt можно обратиться ко всем остальным поисковым системам вместе взятым. Команда в этом случае будет выглядеть так: User-agent: * . Под специальным символом «*» принято понимать «любой текст». В нашем случае – любые другие, кроме Яндекса, поисковики. Гугл, кстати, тоже воспринимает данную директиву на свой счет, если не обращаться лично к нему.
Команда «Disallow:» – запрет индексации в robots.txt
После основной директивы «User-agent:», обращенной к поисковым системам, могут следовать конкретные команды. В их числе самой распространенной можно считать директиву «Disallow: ». При помощи этой команды поисковому роботу можно запретить индексировать веб-ресурс целиком или какую-то его часть. Все зависит от того, какое расширение будет у данной директивы. Рассмотрим примеры:
User-agent: Yandex Disallow: /
Такого рода запись в файле robots.txt означает, что поисковому роботу Яндекса вообще не позволено индексировать данный сайт, так как запрещающий знак «/» стоит в гордом одиночестве и не сопровождается какими-то уточнениями.
User-agent: Yandex Disallow: /wp-admin
Как видно, на этот раз уточнения имеются и касаются они системной папки wp-admin в . То есть индексирующий робот посредством данной команды (прописанному в ней пути) откажется от индексации всей этой папки.
User-agent: Yandex Disallow: /wp-content/themes
Такое указание роботу Яндекса предполагает его допуск в большую категорию «wp-content », в которой он может индексировать все содержимое, кроме «themes ».
Исследуем «запретные» возможности текстового документа robots.txt дальше:
User-agent: Yandex Disallow: /index$
В данной команде, как следует из примера, используется еще один специальный знак «$». Его применение подсказывает роботу, что нельзя индексировать те страницы, в ссылках которых имеется последовательность букв «index ». При этом индексировать отдельный файл сайта с аналогичным названием «index.php » роботу не запрещено. Таким образом, символ «$» применяется в случае, когда необходим избирательный подход к запрету индексации.
Также в файле robots.txt можно запретить индексацию отдельных страниц ресурса, в которых встречаются те или иные символы. Выглядеть это может так:
User-agent: Yandex Disallow: *&*
Эта команда приказывает поисковому роботу Яндекса не индексировать все те страницы веб-сайта, в URL-адресах которых встречается символ «&». Причем этот знак в ссылке должен стоять между любыми другими символами. Однако может быть и другая ситуация:
User-agent: Yandex Disallow: *&
Тут запрет индексации касается всех тех страниц, ссылки которых заканчиваются на «&».
Если с запретом индексации системных файлов сайта вопросов быть не должно, то по поводу запрета индексировать отдельные страницы ресурса такие могут возникнуть. Мол, зачем это нужно в принципе? Соображений на сей счет у опытного веб-мастера может быть много, но главное из них – необходимость избавиться в поиске от дубликатов страниц. С помощью команды «Disallow:» и группы специальных символов, рассмотренных выше, бороться с «нежелательными» страницами можно довольно просто.
Команда «Allow:» – разрешение индексации в robots.txt
Антиподом предыдущей директивы можно считать команду «Allow: ». При помощи тех же самых уточняющих элементов, но используя данную команду в файле robots.txt можно разрешить индексирующему роботу вносить нужные вам элементы сайта в поисковую базу. В подтверждение – очередной пример:
User-agent: Yandex Allow: /wp-admin
По какой-то причине веб-мастер передумал и внес соответствующие корректировки в robots.txt. Как следствие, отныне содержимое папки wp-admin официально разрешено к индексации Яндексом.
Несмотря на то, что команда «Allow:» существует, на практике она используется не так уж и часто. По большому счету в ней нет надобности, поскольку она применяется автоматически. Владельцу сайта достаточно воспользоваться директивой «Disallow:», запретив к индексации то или иное его содержимое. После этого весь остальной контент ресурса, который не запрещен в файле robots.txt, воспринимается поисковым роботом как такой, который индексировать можно и нужно. Все как в юриспруденции: «Все, что не запрещено законом, – разрешено».
Директивы «Host:» и «Sitemap:»
Завершают обзор важных директив в robots.txt команды «Host: » и «Sitemap: ». Что касается первой, то она предназначается исключительно для Яндекса, указывая ему, какое зеркало сайта (с www или без) считать основным. На примере сайт это может выглядеть следующим образом:
User-agent: Yandex Host: сайт
User-agent: Yandex Host: www.сайт
Использование этой команды также позволяет избегать ненужного дублирования содержимого сайта.
В свою очередь директива «Sitemap: » указывает индексирующему роботу правильный путь к так называемой Карте сайта – файлам sitemap.xml и sitemap.xml.gz (в случае с CMS WordPress). Гипотетический пример может быть следующим:
User-agent: * Sitemap: http://сайт/sitemap.xml Sitemap: http://сайт/sitemap.xml.gz
Прописывание данной команды в файле robots.txt поможет поисковому роботу быстрее проиндексировать Карту сайта. Это, в свою очередь, также ускорит процесс попадания страниц веб-ресурса в поисковую выдачу.
Файл robots.txt готов – что дальше?
Предположим, что вы, как начинающий веб-мастер, овладели всем массивом информации, который мы привели выше. Что делать после? Создавать текстовый документ robots.txt с учетом особенностей вашего сайта. Для этого необходимо:
- воспользоваться текстовым редактором (например, Notepad) для составления нужного вам robots.txt;
- проверить корректность созданного документа, например, посредством данного сервиса Яндекса ;
- при помощи FTP-клиента закачать готовый файл в корневую папку своего сайта (в ситуации с WordPress речь обычно идет о системной папке Public_html).
Да, чуть не забыли. Начинающему веб-мастеру, вне всякого сомнения, прежде чем экспериментировать самому, захочется сперва посмотреть на готовые примеры данного файла в исполнении других. Нет ничего проще. Для этого в адресной строке браузера достаточно ввести site.ru/robots.txt . Вместо «site.ru» – название интересующего вас ресурса. Только и всего.
Удачных экспериментов и спасибо, что читали!
Привет, начинающим вебмастерам!
После двух подготовительных уроков ( и ) можем переходить к практической части, а вернее к подготовке сайта к продвижению. Сегодня мы разберем вопрос: как создать robots.txt?
robots.txt – это файл в котором содержатся параметры индексирования для поисковых систем.
Создание этого файла является одним из первых шагов к SEO-продвижению. И вот почему.
Для чего нужен robots.txt?
После того, как вы добавите свой сайт в Яндекс и Google (мы пока это не проходили), ПС начнут индексировать все, абсолютно все, что находится в вашей папке с сайтом на сервере. Это не очень хорошо с точки зрения продвижения, ведь в папке содержится очень много не нужного для ПС “мусора”, что негативно скажется на позициях в поисковой выдаче.
Именно файл robots.txt запрещает индексирование документов, папок и ненужных страниц. Кроме всего прочего, здесь указывается путь к карте сайта (тема следующего урока) и главный адрес, об чуть подробнее.
О карте сайта я говорить много не буду, скажу лишь одно: карта сайта улучшает индексацию сайта. А вот про главный адрес стоит поговорить подробнее. Дело в том, что каждый сайт изначально имеет несколько зеркал (копий сайта) и доступны по различным адресам:
- www.сайт
- сайт
- сайт/
- www.сайт/
При наличии всех этих зеркал сайт становится не уникальным. Естественно, ПС не любят не уникальный контент, не давая таким сайтам подниматься в поисковой выдаче.
Как заполнить файл robots.txt?
Любой файл, предназначенный для работы с различными внешними сервисами, в нашем случае поисковыми системами, должен иметь правила заполнения (синтаксис). Вот правила для robots:
- Название файла robots.txt должно начинаться именно с маленькой буквы. Не нужно называть его ни Robots.txt, ни ROBOTS.TXT. Правильно: robots.txt ;
- Текстовый формат “Unix”. Формат свойственен обычному блокноту в Windows, поэтому создать robots.txt достаточно просто;
Операторы robots
А сейчас поговорим, собственно, о самих операторах robots. Всего их около 6 по-моему, но необходимыми являются только 4:
- User-agent . Данный оператор используется для указания поисковой системы, к которой адресуются правила индексации. С его помощью можно указывать разные правила разным ПС. Пример заполнения: User-agent: Yandex ;
- Disallow . Оператор, запрещающий индексацию той или папки, страницы, файла. Пример заполнения: Disallow: /page.html ;
- Host . Этим оператором указывается главный адрес (домен) сайта. Пример заполнения: Host: сайт ;
- Sitemap . Указывает на адрес карты сайта. Пример заполнения: Sitemap: сайт/sitemap.xml ;
Таким образом я запретил Яндексу индексировать страницу “page.. Теперь поисковый робот Яндекса учтет эти правила и страницы “page.html” никогда не будет в индексе.
User-agent
Как уже было сказано выше, в User-agent указывается поисковая система, к которой будут использованы правила индексации. Вот небольшая табличка:
| Поисковая система | Параметр User-agent |
| Яндекс | Yandex |
| Mail.ru | Mail.ru |
| Rambler | StackRambler |
Если вы хотите, чтобы правила индексации применялись для всех ПС, то нужно сделать такую запись:
User-agent: *
То есть, использовать, как параметр, обычную звездочку.
Disallow
С этим оператором чуть посложнее, поэтому нужно быть осторожным с его заполнением. Прописывается после оператора “User-agent”. Любая ошибка может привести к очень плачевным последствиям.
| Что запрещаем? | Параметр | Пример |
| Индексацию сайта | / | Disallow: / |
| Файл в корневом каталоге | /имя файла | Disallow: /page.html |
| Файл по определенному адресу | /путь/имя файла | Disallow: /dir/page.html |
| Индексация папки | /имя папки/ | Disallow: /papka/ |
| Индексация папки по определенному адресу | /путь/имя папки/ | Disallow: /dir/papka/ |
| Документы, начинающиеся с определенного набора символов | /символы | /symbols |
| Документы, начинающиеся с определенного набора символов по адресу | /путь/символы | /dir/symbols |
Еще раз говорю: будьте крайне внимательны при работе с данным оператором. Случается и такое, что чисто случайно человек запрещает индексацию своего сайта, а потом удивляется тому, что его нет в поиске.
Про остальные операторы говорить смысла нет. Того, что написано выше вполне достаточно.
Вам, наверное, хотелось бы получить пример robots.txt? Ловите:
User-agent: * Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /trackback Disallow: */trackback Disallow: */*/trackback Disallow: */*/feed/*/ Disallow: */feed Disallow: /tag Host: site.ru Sitemap:site.ru/sitemap.xml
Кстати, этот пример могут использовать, как настоящий файл robots.txt, люди, чьи сайты работают на WordPress. Ну а те, у кого обычные сайты, пишите сами, ха-ха-ха. К сожалению, одного единственного для всех не существует, у каждого он свой. Но с той информацией, которую я вам дал, создать robots.txt не составит большого труда.
До свидания, друзья!
Всем привет! Начну с важного объявления. В нашем блоге запускается проект «Технический аудит под микроскопом » и данный материал открывает цикл статей, посвященных этой теме. О чем пойдет речь сегодня? О том, как правильно написать robots.txt для сайта с нуля.
Текст советую прочесть тем, кто хочет научиться создавать текстовый файл самостоятельно, и рассмотреть принцип его работы изнутри. Информация также пригодится владельцам веб-проектов, которые стремятся продвинуть свой сайт в ТОП.
В статье ниже «под микроскопом» рассмотрены такие вопросы:
Чтобы написать статью, я потратила около 37 часов, изучила более 20 источников, посетила несколько форумов веб-мастеров. Поэтому каждое слово неоднократно проверено и перепроверено.
Итак, начнем. Чтобы ввести вас в тему и дать общее представление о robots.txt, предлагаю по традиции обратиться к ассоциациям. Представьте, что вы владелец дома, и, как водится в частном секторе, к вам постоянно кто-то из соседей приходит в гости. Как вы можете поступить? Вообще не открывать дверь никому или впускать некоторых, которые более симпатичны. При этом вы можете предоставить в распоряжение гостей весь дом или только отдельные комнаты, закрыв все личные апартаменты.
По такому принципу и работает robots.txt: что-то для кого-то открывает, а куда-то кого-то не пускает. Подробности читайте дальше в статье.

Robots.txt: что значит и как работает
Знакомство с индексным файлом логично начать с объяснения термина.
Robots.txt – текстовый документ, который говорит поисковикам, на какие данные и страницы сайта обращать внимание (индексировать, обрабатывать), а на какие нет. Его еще называют «стандартом/протоколом исключений для роботов». Он действует для протоколов https, http и FTP, использует кодировку UTF-8 Unicode.
Практически все популярные поисковые системы следуют данным стандартам: Google, Ask, Yandex, AOL, Yahoo!, Bing и др. Хотя, стоит отметить, что Гугл воспринимает их, как «рекомендации», а не как «команду». То есть, как я понимаю, хочу придерживаюсь, хочу – нет.
Где находится файл robots.txt? Его размещают в корневом каталоге веб-проекта. Визуально он выглядит так:
https://site.com.ua/robots.txt.
Принцип работы robots.txt
Говоря простыми словами, наличие robots.txt помогает установить диалог между веб-проектом и поисковыми системами (как переводчик на переговорах). При этом владелец ресурса сам решает, куда открыть доступ и куда запретить вход.
Таким образом, после сканирования индексного файла, развитие событий идет по одному из 3-х сценариев, т.е. поисковики получают:
- полный доступ ко всему веб-ресурсу;
- частичный пропуск, т.е. только к разрешенным страницам и данным;
- абсолютный запрет на вход, где сайт полностью закрыт для обработки.
Чтобы показать, как проходит индексация веб-проекта с robots.txt и без него, сделала инфографику.

Чтобы понять важность данного файла, нужно знать принцип работы поисковых систем. Итак, как же они действуют?
Робот поисковика заходит на сайт и первым делом ищет robots.txt. Если его нет или он составлен неправильно, то поисковая система начинает «руководить парадом» самостоятельно. То есть сканирует все подряд: и нужное, и ненужное. При таком подходе обработка веб-ресурса затягивается надолго и при этом не факт, что важные страницы будут первыми в очереди. Зачем такие сложности?
Кроме того, за 1 посещение роботы обрабатывают определенное число ресурсов. Какой из этого следует вывод? Меньше страниц для сканирования, больше проиндексированных и, следовательно, больше трафик. Быстрая индексация также помогает защитить новый контент и отследить, как те или иные мероприятия повлияли на позиции в выдаче.

5 основных директив для написания robots.txt
Прежде чем начать создавать файл robots.txt, нужно ознакомиться с основными командами (директивами), которые понадобятся для написания списка запретов.
Есть 5 базовых команд:
USER-AGENT
Указывает, для какого поисковика предназначаются команды, которые следуют после нее. Можно использовать символ «*» и тогда указания будут касаться всех поисковых систем. С этой директивы начинается любой индексный файл. Если она не прописана, поисковый робот считает, что все двери для него открыты.
Например:
User-agent: Google – команды для Гугл
User-agent: Yandex – команды для Яндекс
User-agent: * – команды для всех поисковиков
Обратите внимание, если робот обнаружил название своего поисковика после директивы User-agent, он проигнорирует все указания из раздела «User-agent: *».
Важно отметить, что поисковые системы имеют несколько роботов, для каждого из которых нужно прописывать команды отдельно.
Рассмотрим базовые роботы самых популярных поисковиков Гугл и Яндекс:
1. Google:
- Googlebot – основной робот поисковика;
- Googlebot-Image – сканирует изображения;
- Googlebot-Video – проверяет видеофайлы;
- Googlebot-Mobile – обрабатывает страницы для мобильных гаджетов;
- Adsbot-Google – проверяет качество рекламы на ресурсах для ПК;
- Googlebot-News – ищет страницы, чтобы добавить в Гугл Новости.
2. Yandex:
- Yandex – означает, что команды относятся ко всем роботам Яндекс;
- YandexBot – базовый бот поисковика;
- YandexImages
– обрабатывает картинки;
YandexNews – индексатор страниц, предназначенных для Яндекс Новости; - YandexMedia – сканирует мультимедийные данные;
- YandexMobileBot – проверяет документы на предмет верстки под мобильные девайсы.
Запомните, при написании файла robots.txt секции для разных ботов нужно разделять 1 пустой строкой.
В качестве памятки:

DISALLOW и ALLOW
Здесь все просто. Директива Allow разрешает поисковым ботам сканировать ресурс, Disallow – запрещает. Рассмотрим подробнее, как они работают.
Если в файле robots.txt прописать запрещающую команду Disallow или Allow, то можно:
- закрыть/открыть доступ роботов ко всему сайту, используя слэш;
Disallow: /
Allow: /
- запретить/разрешить сканирование определенных страниц, прописав адрес.
Disallow: /admin/
Allow: /admin/
- открыть/закрыть вход к конкретному файлу, указав путь:
Disallow: /razdel/file
Allow: /razdel/file
- запретить/разрешить обрабатывать документы определенного типа, используя *:
Disallow: /*png*
Allow: /*png*
Обратите внимание, чтобы закрыть/открыть страницы сайта для индексации, после данных директив robots.txt пишется не полный адрес, а лишь та часть, которая идет после домена сайта..
Как видите, все действительно просто. Как в математике: знаешь формулу – решишь задачу.
Чтобы закрепить материал, давайте разберем пример:
User-agent: *
Disallow: /
Allow: / blog/
Allow: / *.gift*
Что мы видим в фрагменте этого robots.txt: доступ открыт для всех поисковых систем, закрытыми для сканирования являются все страницы, кроме одного раздела «blog» и файлов типа «.gift».
Скачивайте картинку ниже, чтобы не забыть:

Что можно закрыть с помощью файла robots.txt и Disallow?
Все, конечно, зависит от пожеланий владельца веб-проекта, но есть несколько общих рекомендаций.
Посредством robots.txt советуют запретить индексацию ресурсов с:
- административной частью (иначе говоря, админку);
- личными данными пользователей;
- неполезным, неактуальным или неуникальным контентом (чек-лист для проверки);
- многоуровневыми формами регистрации, обратной связи, заказа и корзиной;
- тегами, результатами поиска по сайту, фильтрами.
Делаем вывод – в файле robots.txt нужно закрыть те страницы сайта, которые не важны, не нужны или не должны быть показаны пользователям и поисковикам.
Кстати, статья о контенте: «2 вида визуального контента »

SITEMAP
Еще один директив, который должен быть написан в файле robots.txt – Sitemap. Для чего он служит? Чтобы показать поисковым ботам путь к Карте сайта. Разберем вопрос в деталях.
Карта сайта – это файл в формате xml с кодировкой UTF8, который хранится в корневой директории веб-ресурса. Он представляет собой своеобразный каталог с ссылками, что ведут на разные страницы. При составлении Карты важно вносить только те ресурсы, которые нуждаются в индексе, исключая с динамическим URL и тегами.
Основные требования к файлу смотрите ниже:

Как директива Sitemap помогает в индексации?
Вспоминаем принцип работы поисковых ботов: зашли на сайт, откинули закрытые страницы и далее, если нет данной команды, начинают хаотично рыскать по сайту. Так как время на сканирование одного веб-проекта ограничено, робот может так и не дойти до действительно важных ресурсов. Особенно это касается «больших» сайтов, где много страниц и переходов по ссылкам.
Будет интересно прочесть: «Покупка вечных ссылок: 4 шага от хаоса к порядку »
Здесь как раз и приходит на помощь директива Sitemap. Она провожает робота к Карте сайта, где указано, какие ресурсы нужно проиндексировать и какие являются самыми важными, а также как часто должна обновляться информация. Такая индексация 100% более качественная и быстрее в 3,14 раза.
Вот как выглядит готовая Карта сайта (фрагмент):

Как создать Карту сайта?
Идеальный вариант воспользоваться бесплатными онлайн-генераторами.
Вот список протестированных мной сервисов:
- XML-Sitemaps.com. Бесплатно создает Sitemap для сайтов, содержащих до 500 страниц. Время работы – 2-3 минуты. Предлагает скачать файл в формате XML Document. Не требует регистрации. Интерфейс на английском языке.
- mysitemapgeneration . Для бесплатного пакета ограничение – до 500 страниц. Создание Карты сайта занимает всего пару минут. Готовый файл в формате xml отправляется на почту. Сайт русифицирован, простой и понятный. Регистрироваться не нужно.
- Xml Sitemap Generator . Англоязычный ресурс с лимитом до 2000 страниц. Скачать файл можно в нескольких форматах: xml, rss, html, txt. Создание Карты сайта проходит также быстро и без регистрации.
- Majento. Русскоязычный оперативный сайт, не требующий регистрации. Лимиты бесплатного пакета: до 1000 страниц, 5 раз/сутки для одного IP-адреса. Можно определить параметры отчета и установить фильтр на страницы с определенным расширением. Готовую Карту сайта можно скачать в формате xml.
Все сервисы справляются с созданием Sitemap на отлично. Кроме представленных онлайн-генераторов, есть также множество других: Small Seo Tools, Screamingfrog, xSitemap.com, Free Sitemap Generator и т.д. Выбирайте самый оптимальный для себя и делайте Карты сайта без проблем.
Узнайте также о 5 лучших сервисах для работы копирайтера с текстом
В готовом файле, кроме URL-адресов, вы увидите несколько команд, расшифровать которые поможет следующая картинка:

Карта сайта готова. Что дальше?
Нужно оповестить об этом поисковые системы. Конечно, поисковики со временем сами обнаружат этот файл, но для ускорения процесса лучше сразу показать им путь.
Вот 2 самых простых способа рассказать поисковым ботам о Карте сайта:
- Добавить ссылку на адрес файла, используя панель инструментов вебмастеров от Google и Yandex. В Яндекс.Вебмастер нужно: нажать на вкладку «Индексирование», далее на «Файлы Sitemap» и ввести URL. Для Гугл: открываем Google Search Console, кликаем на «Сканирование», затем на «Файлы Sitemap», вставляем и отправляем адрес.
- Вставить в файл robots.txt ссылку на месторасположение файла Sitemap. Визуально это выглядит так: Sitemap: https://site.com/sitemap.xml
Важный совет в заключении – желательно добавлять Sitemap после каждой публикации новой информации на сайте.
Как еще ускорить индексацию читайте:
«Как разместить и ускорить индексацию статьи? 5 секретов успеха »
HOST
Последней неотъемлемой частью robots.txt была директива Host. Она показывала поисковому роботу, какое зеркало (алиас) веб-проекта является основным: с префиксом www или без. Воспринималась данная команда только поисковиком Yandex и была актуальной исключительно для сайтов, имеющих «копии».
Примечание : зеркало сайта представляет собой полную или частичную копию интернет-проекта, которая имеет свой домен и находится на отдельном ресурсе.
Выглядело это примерно так:

Почему все в прошедшем времени, спросите вы. Ответ простой – 20 марта 2018 года Яндекс официально объявил про отказ от директивы Host. Теперь данная команда должна быть заменена редиректом 301 через файл.htaccess. Директиву Host нужно просто удалить из индексного файла. Хотя, если она присутствует, ничего страшного не произойдет, т.к. Яндекс теперь ее просто игнорирует.
Использование редиректа 301 для определения основного сайта является универсальным способом, т.к. воспринимается всеми поисковыми ботами. Детально, как поставить 301-й редирект будет рассказано в следующей статье. Следите за новинками в блоге, посещая сайт или через ленту новостей в